6 月 13 日,笔神作文发布 " 关于‘学而思’ AI 大模型侵权事件的声明 "。声明称,4 月 13 日至 17 日,学而思通过 " 爬虫 " 技术非法访问、缓存笔神作文 APP 服务器数据多达 258 万次。严重侵犯了笔神作文 APP 的数据权益。
对此,学而思官方微博发文回应称:" 首先,MathGPT 是专注于数学领域的自研大模型,没有任何作文相关数据;其次,‘作文 AI 助手’目前处于开发状态,尚未发布,该服务并未使用笔神作文的任何数据。"
6 月 14 日,笔神作文再度发文,在这篇题为《学而思,你做了一次标准的扒库示范》的声明中,其表示 " 我们认为学而思方所述并非事实 ",并列出了相关证据。
受访专家向 21 世纪经济报道记者分析,本次风波的实质是授权合同违约纠纷,涉及到对于合同授权范围条款的解释。AIGC 产品获得训练模型数据授权是合规的根基。
学而思 AI 大模型疑盗取合作商数据?
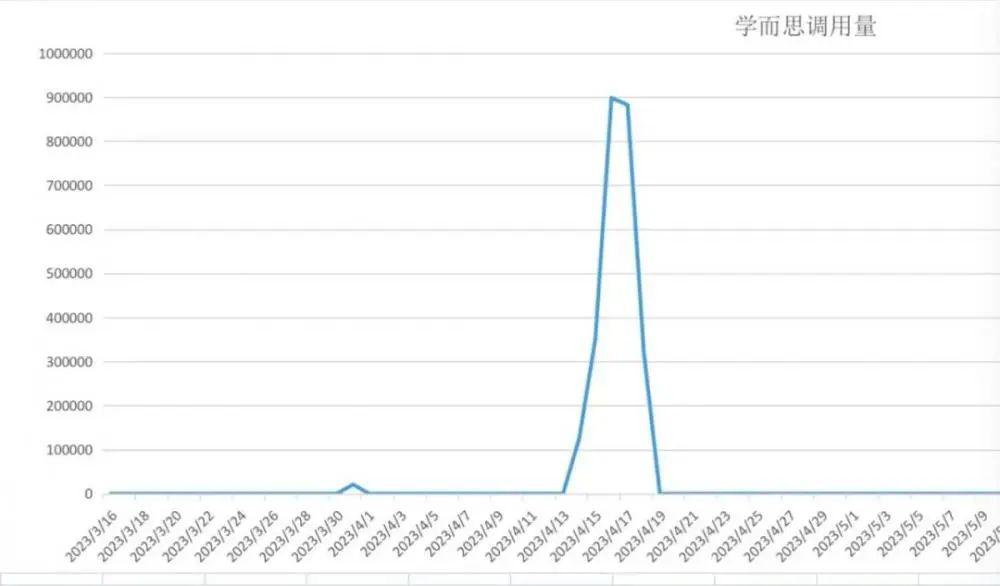
" 学而思在今年 4 月 13 日至 4 月 17 日,通过‘爬虫’技术非法访问、缓存笔神作文 APP 服务器数据多达 258 万次。" 笔神作文在 6 月 13 日声明中表示。
笔神作文认为,这一行为不仅违反了双方的合同条款,也违反了《数据安全法》相关规定,严重侵犯了笔神作文 APP 的数据权益。事后其曾向学而思方面进行取证,并且对方承认是他们的算法组在爬取数据并作为己用,但在收到律师函后始终没有实质性答复。
记者了解到,笔神作文是隶属于北京一笔两划科技有限公司的品牌,据其官网介绍,笔神是一款人工智能辅助写作软件,拥有千万级写作素材库。笔神作文与学而思之间有着多年的合作基础。
笔神作文称,在不到一个月的时间,学而思的 AI 大模型 MathGPT 里包含的新产品 " 作文 AI 助手 " 就即将上线。疑似指后者作文 AI 产品使用了其数据。
笔神作文还表示会通过法律途径来维护自身权益,但目前国内并没有 "AI 大模型数据盗取 " 的判决先例。" 希望学而思就此支付 1 元赔偿金,并公开道歉,同时删除已爬取的数据。"
各执一词:正常合作还是 " 扒库 " 行为?
6 月 13 日晚,学而思发布声明,从三方面进行回应:
一是,学而思和笔神作文于 2020 年 12 月开始合作,合作协议明确约定:笔神作文为学而思提供 " 笔神作文范文素材服务接口 ",用于学而思相关服务中,每月保底费用包含的调用次数为百万次量级。合作至今,双方一直按照调用量进行正常结算。
二是,学而思对笔神作文接口的调用,属于双方合同约定的正常合作范围,对笔神素材内容的使用均符合合同要求,并未用于合同以外的任何用途。
三是,笔神作文在公开声明中提及学而思正在研发的数学大模型 MathGPT 以及学而思学习机 " 作文 AI 助手 ",并主观揣测学而思使用其数据用于两款产品的训练和研发,这与事实严重不符。
" 首先,MathGPT 是专注于数学领域的自研大模型,没有任何作文相关数据;其次,作文 AI 助手目前处于开发状态,尚未发布,该服务并未使用笔神作文的任何数据。" 学而思称。
6 月 14 日,笔神作文发布《学而思,你做了一次标准的扒库示范》,表示 " 我们认为学而思方所述并非事实 ",并列出相关证据。
笔神作文称,学而思在声明里提到调用数据为正常使用,笔神作文在合同中明确 " 甲方(注:三体云联公司)不得随意泄露、使用、传播或缓存乙方(注:一笔两划公司)服务接口中的作文范本及相关内容,否则造成的损失将由甲方全额赔偿 "。同时,在合同中提出 " 甲方不得在未经乙方允许的情况下用于任何其他用途,包括缓存,存储,作为语料进行计算,训练等。"
但在 2023 年 4 月 13 日至 4 月 17 日之间,笔神作文检测到服务器接口出现大量有规律的异常访问,导致服务器承载压力快速升高。通过查阅服务器日志发现:三体云联公司未经一笔两划公司授权许可,用单一 IP 通过 " 爬虫 " 技术非法访问一笔两划公司服务器数据多达 258 万次。
(图源:笔神作文 APP 微信公众号)
" 而且,从这个 IP 的访问日志来看,每次访问的搜索词都是作文相关的高频搜索词,我们每页会返回 30 篇作文,每次访问都是用搜索词从第一页逐页向后翻,这种方式基本上把库里同个题目的所有作文全部抓取完了,这种行为不是正常人使用的方式。而且很多访问的间隔都是 100 毫秒左右,也不可能是正常人访问的速度。" 笔神作文表示。

(图源:笔神作文 APP 微信公众号)
笔神作文认为,这种对数据库的搜刮式访问,与以往正常的访问方式完全不同,按业内的通常说法,这就是一种典型的 " 扒库 " 行为。
网络安全专家陈业炫告诉 21 世纪经济报道记者,所谓 " 扒库 " 是一个口语化的形容词,用于形容大规模爬取数据。" 数据爬虫过程中,爬取的规模大了、频率高了,就会被认为是非正常行为。通常情况下,高频率的请求,大规模、每一篇都会访问的遍历式行为都需引起关注。"
据陈业炫介绍,爬虫本身就是程序化的自动行为,比如每秒 10 次的访问量可以看作是超出普通用户的行为频率,正常用户不会大规模、高频率的访问相关网页。
在这个事件中,哪些行为是被允许的?哪些是不被允许的?" 笔神允许相关合作方查询、查看数据,但是不能本地化存储用于机器学习的素材。" 陈业炫说。
据笔神作文介绍,基于双方的合作精神,笔神作文自己的技术团队设计了完备的安全机制,正常情况下,可以防止黑客们进行爬虫攻击。而只有提供给合作伙伴学而思的接口是不设防的。
如何理解接口不设防?陈业炫介绍,笔神作文方面未对学而思设置反爬虫措施。" 日常的合作中,开放数据的一方通常需要限制访问的行为,包括频率和总量,给自己留以一定的反应时间,以防全部数据被快速抓走。"
21 世纪经济报道记者多次通过官方电话尝试联系事件双方,截至发稿前未得到回复。
AIGC 火爆出圈,与之伴生的侵权风险问题也引发各界关注。国家网信办今年 4 月发布的《生成式人工智能服务管理办法(征求意见稿)》提到,提供者应当对生成式人工智能产品的预训练数据、优化训练数据来源的合法性负责。用于生成式人工智能产品的预训练、优化训练数据不得含有侵犯知识产权的内容。
中伦律师事务所合伙人王飞指出,以 ChatGPT 为代表的生成式 AI,底层是一款通用的自然语言生成模型,通过互联网海量的语料库训练,对语言文本进行概率建模来预测下一段输出内容的概率,从而实现根据用户输入的文字内容生成对应文字回答的功能。
具体到本次学而思和笔神作文的 "AI 大模型数据窃取 " 风波,王飞表示,这个事件实质是授权合同违约纠纷,涉及到对于合同授权范围条款的解释。AIGC 产品获得训练模型数据授权是合规的根基,授权的内容和范围、使用的形式等一般会在签订授权合同时予以明晰,但鉴于 AIGC 作为新生产物,怎样进行约定还要再进行探索,也会是未来 AIGC 产品纠纷产生的主要原因之一。
陕西华格律师事务所律师葛伟超也认为,这主要是基于合同目的而产生的问题。" 双方可能会因为合同中关于数据使用的范围、方式、程度等条款约定不明产生不同理解,而对簿公堂。"
那么,构成 AI 大模型 " 数据盗取 " 行为,有哪些主要的判断因素?
"AI 数据抓取案件本质上与近年来司法判决的典型数据抓取案件并无差别,都需要判断抓取数据行为是否损害数据持有者的商业利益与市场竞争优势、是否属于未经许可使用他人劳动成果、是否违背商业道德、抓取数据是否有合理理由。" 王飞说。
在法律责任方面,葛伟超指出,利用抓取技术破坏他人市场竞争优势,具有并存在为自己谋取竞争优势的主观故意,违反诚实信用原则,扰乱竞争秩序的数据抓取行为,可能构成不正当竞争行为。同时也直接违反了《数据安全法》相关规定。
" 如果合作协议中有约定违约责任条款,则依其处理。如果没有约定该种情形,则属于侵权范围,要承担相应侵权责任,包括但不限于赔礼道歉、停止侵权、赔偿损失等。" 葛伟超说。
大模型的开发离不开海量数据助力。当前,数据来源的知识产权已经成为大模型发展的阿喀琉斯之踵。AI 模型开发主体以何种方式、需要承担何种程度的法律义务以获取训练数据,是当前产业需要解决的核心问题。
值得关注的是,传统的 " 授权许可模式 " 对于大模型的数据训练存在天然困境,不仅在于实操层面难以落地,更在于对产业研发的长期影响。业界有观点认为,可以将数据纳入合理使用的范畴进行规制。
目前来看,日本、英国、欧盟等已对将数据挖掘作为合理使用的情形进行了立法确认:日本以 " 计算机信息分析 " 的名义规定了文本数据挖掘的著作权例外,英国同样引入文本和数据挖掘的版权许可或例外情况,欧盟则选择 " 非科研目的 " 例外的谨慎方案。中国业内也在探讨是否可以通过数据的合理使用解决数据权属带来的问题。
对于如何厘清数据合理使用和保护的边界,葛伟超认为," 首先,要明确拥有数据的经营者权利,即拥有数据所有权还是数据用益权。其次,明确数据抓取行为的性质。再次,明确该种行为损害的法益是数据财产还是竞争优势。最后,需要明确规制该种行为到底适用于竞争法、民法、或者著作权法的保护。"