作者:Adam Geitgey
译者:巡洋舰科技——赵95
校对:离线Offline——林沁
转载请联系译者。
你是不是看烦了各种各样有关深度学习的报道,却仍不知其所云?让我们一起来改变这个现状吧!
这一次,我们将应用深度学习技术,来写一个识别图像中物体的程序。换句话说,我们会解释 Google 相册搜索图片时所用到的「黑科技」:
Google 现在可以让你在你自己的图片库里面,根据你的描述搜索图片,即使这些图片根本没有被标注任何标签!这是怎么做到的??
和第一、二章一样,这篇指南是为那些对机器学习感兴趣,但又不知从哪里开始的人而写的。这意味着文中有大量的概括。但是那又如何呢?只要能让读者对机器学习更感兴趣,这篇文章的任务也就完成了。
用深度学习识别物体

xkcd#1425(出自http://xkcd.com,汉化来自http://xkcd.tw)
你可能曾经看过这个著名的 xkcd 的漫画。
一个 3 岁的小孩可以识别出鸟类的照片,然而最顶尖的计算机科学家们已经花了 50 年时间来研究如何让电脑识别出不同的物体。漫画里的灵感就是这么来的。
在最近的几年里,我们终于找到了一种通过深度卷积神经网络(deep convolutional neural networks)来进行物体识别的好方法。这些个词听起来就像是威廉·吉布森科幻小说里的生造词,但是如果你把这个想法逐步分解,你绝对可以理解它。
让我们开始吧——让我们一起来写一个识别鸟类的程序!
由浅入深
在我们在识别鸟类之前,让我们先做个更简单的任务——识别手写的数字「8」。
在第二章中,我们已经了解到神经网络是如何通过连接无数神经元来解决复杂问题的。我们创造了一个小型神经网络,然后根据各种因素(房屋面积、格局、地段等)来估计房屋的价格:
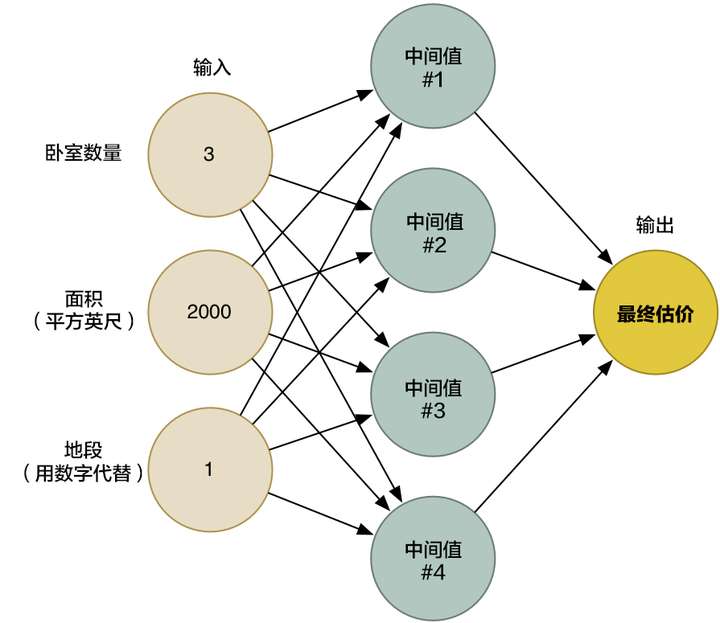
在第一章中我们提到了,机器学习,就是关于重复使用同样的泛型算法,来处理不同的数据,解决不同的问题的一种概念。所以这次,我们稍微修改一下同样的神经网络,试着用它来识别手写文字。但是为了更加简便,我们只会尝试去识别数字「8」。
机器学习只有在你拥有数据(最好是大量数据)的情况下,才能有效。所以,我们需要有大量的手写「8」来开始我们的尝试。幸运的是,恰好有研究人员建立了 MNIST 手写数字数据库,它能助我们一臂之力。MNIST提供了 60,000 张手写数字的图片,每张图片分辨率为 18×18。下列是数据库中的一些例子:

万物皆「数」
在第二章中我们创造的那个神经网络,只能接受三个数字输入(卧室数、面积、地段)。但是现在,我们需要用神经网络来处理图像。所以到底怎样才能把图片,而不是数字,输入到神经网络里呢?
结论其实极其简单。神经网络会把数字当成输入,而对于电脑来说,图片其实恰好就是一连串代表着每个像素颜色的数字:

我们把一幅 18×18 像素的图片当成一串含有 324 个数字的数组,就可以把它输入到我们的神经网络里面了:

为了更好地操控我们的输入数据,我们把神经网络的输入节点扩大到 324 个:
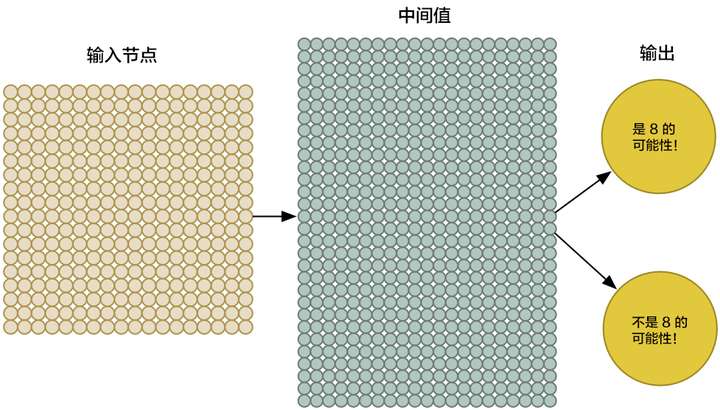
虽然我们的神经网络要比上次大得多(这次有 324 个输入,上次只有 3 个!),但是现在的计算机一眨眼的功夫就能够对这几百个节点进行运算。当然,你的手机也可以做到。
现在唯一要做的就是用各种「8」和非「8」的图片来训练我们的神经网络了。当我们喂给神经网络一个「8」的时候,我们会告诉它是「8」的概率是 100% ,而不是「8」的概率是 0%,反之亦然。
下面是一些训练数据:

嗯……训练数据好好吃
在现代的笔记本电脑上,训练这种神经网络几分钟就能完成。完成之后,我们就可以得到一个能比较准确识别字迹「8」的神经网络。欢迎来到(上世纪八十年代末的)图像识别的世界!
短浅的目光
仅仅把像素输入到神经网络里,就可以识别图像,这很棒!机器学习就像魔法一样!……对不对?
呵呵,当然,不会,这么,简单。
首先,好消息是,当我们的数字就在图片的正中间的时候,我们的识别器干得还不错。

坏消息是:
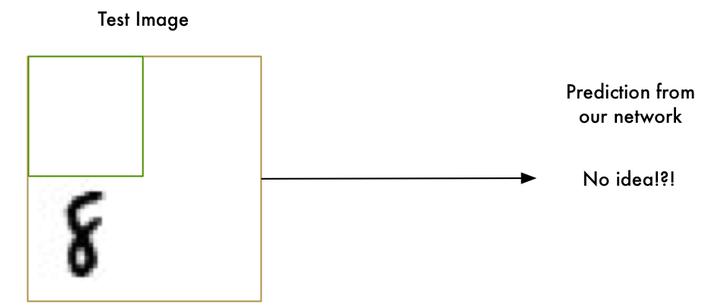
当数字并不是正好在图片中央的时候,我们的识别器就完全不工作了。一点点的位移我们的识别器就掀桌子不干了(╯‵□′)╯︵┻━┻。

这是因为我们的网络只学习到了正中央的「8」。它并不知道那些偏离中心的「8」长什么样子。它仅仅知道中间是「8」的图片规律。
在真实世界中,这种识别器好像并没什么卵用。真实世界的问题永远不会如此轻松简单。所以,我们需要知道,当「8」不在图片正中时,怎么才能让我们的神经网络识别它。
暴力方法 #1:滑框搜索
我们已经创造出了一个能够很好地识别图片正中间「8」的程序。如果我们干脆把整个图片分成一个个小部分,并挨个都识别一遍,直到我们找到「8」,这样能不能行呢?
暴力方法 #2:更多的数据与一个深度神经网
刚刚我们提到,经过训练之后,我们只能找出在中间的「8」。如果我们用更多的数据来训练,数据中包括各种不同位置和大小的「8」,会怎样呢?
我们并不需要收集更多的训练数据。实际上,我们可以写一个小脚本来生成各种各样不同位置「8」的新图片:
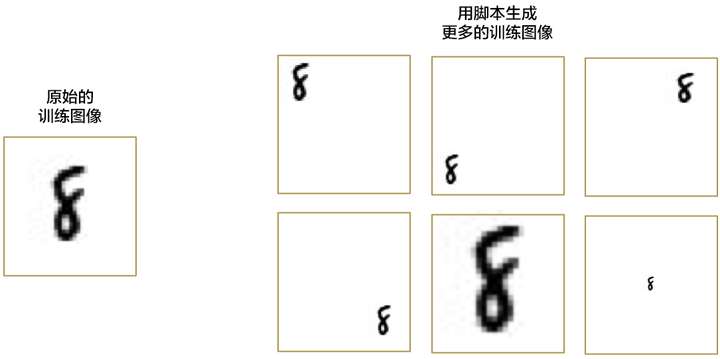
使用这种方法,我们能够轻易地创造出无限量的训练数据。
数据越多,这个问题对神经网络来说就越复杂。但是通过扩大神经网络,它就能寻找到更复杂的规律了。
要扩大我们的网络,我们首先要把把节点一层一层的堆积起来:
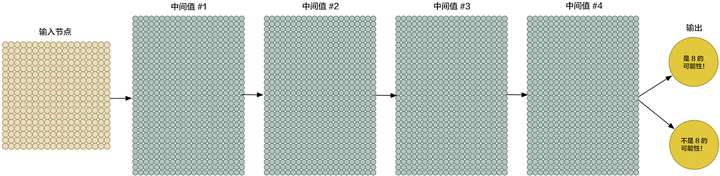
这个想法在二十世纪六十年代末就出现了,但直至今日,训练这样一个大型神经网络也是一件缓慢到不切实际的事情。然而,一旦我们知道了如何使用 3D 显卡(最开始是用来进行快速矩阵乘法运算)来替代普通的电脑处理器,使用大型神经网络的想法就立刻变得可行了。实际上,你用来玩守望先锋的 NVIDIA GeForce GTX1080 这款显卡,就可以极快速的训练我们的神经网络。

仔细想想,如果把图片最上方和最下方的「8」当成两个不同的对象来处理,并写两个不同的网络来识别它们,这件事实在是说不通。
应该有某种方法,使得我们的神经网络,在没有额外的训练数据的基础上,能够非常智能的识别出图片上任何位置的「8」,都是一样是「8」。幸运的是……这就是!
 选择“Disable on www.wenxuecity.com”
选择“Disable on www.wenxuecity.com”
 选择“don't run on pages on this domain”
选择“don't run on pages on this domain”